

With the advent of machine learning, AI models have become more accurate and efficient, paving the way for various applications in industries such as finance, healthcare, and gaming. However, developing an AI model that can accurately predict outcomes requires significant efforts in data collection, preprocessing, and model training. AI model training and fine-tuning is a crucial step in the process of developing an AI model that can learn from the data it is fed and make accurate predictions. This article will delve into the details of AI model training and fine-tuning, exploring the different techniques and algorithms used to optimize the model's performance.
AI Model Training
AI model training refers to the process of teaching an artificial intelligence algorithm to recognize and respond to specific patterns and inputs. This is a critical step in developing an effective AI system that can perform tasks and make decisions similar to those made by humans. The training process involves providing the algorithm with a vast amount of data and feedback to help it learn and improve over time.
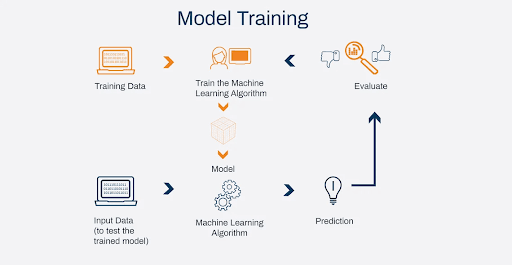 Image credit: Columbus
Image credit: Columbus
During the training process, the AI algorithm learns by analyzing data, identifying patterns, and adjusting its behavior based on feedback from its environment. This process typically involves the use of machine learning techniques, which allow the algorithm to learn and adapt on its own without explicit instructions from a human operator.
One of the key benefits of AI model training is that it enables machines to perform complex tasks and decision-making processes with a high degree of accuracy and efficiency. For example, an AI system trained to recognize images could easily identify objects in a photograph or video, even in complex and varied environments.
The success of AI training relies heavily on the quality and quantity of data provided to the algorithm. To achieve the best possible results, AI model training must involve large amounts of high-quality data that accurately reflect the problem or task being solved. This data must also be carefully structured and labeled to ensure that the algorithm can effectively learn and generalize from it.
Note: the process of AI model training can be time-consuming and expensive, as shown by the $100 million cost to train GPT-4, which powers ChatGPT. Despite this, many companies choose to use pre-trained models as a cost-effective alternative. These models have already been trained on large amounts of data, making them suitable for many applications.
AI Fine-Tuning
Fine-tuning is the process of tweaking an existing pre-trained model to make it adapt to a new or more specific task. Imagine you have a model that excels at recognizing objects in images but you want it to identify the subtle differences between cat breeds. Fine-tuning is the pathway to that refinement. This practice is a subset of transfer learning, where knowledge from a pre-existing model is transferred to a similar yet distinct domain.
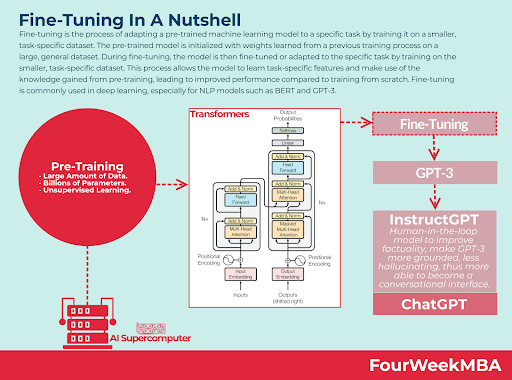
When an AI model is trained, its parameters are tuned to a unique set of features in the data. Fine-tuning, however, re-adapts some of these parameters to a subset of new data, leveraging learning from the original tuning but leaning towards the new requirements.
When Should You Fine-Tune an AI Model?
While the initial training phase sets the foundation for model performance, fine-tuning becomes crucial under various circumstances:
- Domain Shift: When the distribution of data in your new problem substantially differs from that of the original training data.
- Task Change: Transitioning from a general to a more specialized task, requiring subtle but important changes.
- Resource Constraints: Leveraging pre-existing models for a head start and reducing the need for large-scale raw data and computational resources.
- Depth of Understanding: Fine-tuning allows the model to learn and emphasize finer patterns and cues, fitting more intimately with the specificities of the new data.
Preparing for Fine-Tuning
- Data Quality Check. Just like in the initial training, the right and relevant data is imperative. Assess the quality, quantity, and representativeness of your dataset. Any biases, anomalies, or noise might lead to counterproductive results.
- Model Selection. Choosing the right pre-trained model that reflects the closest domain or task correlation to your fine-tuning goals is essential. Popular architectures like BERT for natural language processing tasks or ResNets for image-related tasks.
- Objective and Metrics. Defining your new task with clear objectives and a set of evaluation metrics is necessary. This not only guides the fine-tuning process but also ensures you can measure its success accurately.
Feature Extractor
In some cases, you may fix the bottom layers of the model – the feature extractor – while training only the top layers on task-specific data. This prevents the feature extractor from 'forgetting' its original training and allows for quicker adaptation to the current task.
Learning Rate Adjustment
The learning rate, the step size used during training to update the weights, is typically reduced during fine-tuning to stabilize the model's adjustments to the new data and task.
Regularization and Loss Function
Applying appropriate regularization techniques – such as dropout or weight decay – helps prevent overfitting, particularly when fine-tuning on a smaller dataset. Ensuring the loss function aligns with the new task also boosts convergence.
Gradual Unfreezing
Instead of fine-tuning all layers at once, gradually unfreezing layers, starting from the output layers and moving downwards, enables a more balanced and steady re-learning process for each layer.
I want to fine tune my model. Book a 30-min. consultation
Request a free callFine-Tuning in Action
Here's an illustrative walkthrough for fine-tuning a pre-trained natural language processing (NLP) model like GPT-3 for a new token-classification task:
- Data Preparation: Collate and pre-process your annotated dataset for the new task, ensuring it's compatible with the model's format.
- Initialization: Load the pre-trained GPT-3 model and set up token classification head with the right architecture and format.
- Training Loop: During each epoch, feed the training data into your fine-tuned model, calculate the loss, and backpropagate through the network to update the weights with the adjusted learning rates.
- Validation: Monitor the model's performance on the validation set by calculating the appropriate token classification accuracy and loss.
- Unfreezing: Unfreeze the last few layers of GPT-3 and continue training to observe further performance improvements.
The proficiency of fine-tuning AI models heralds a new echelon of possibilities. It enables models to specialize, optimize, and evolve, rendering ML applications not just powerful, but adaptable over time.
Industries are harnessing AI and fine-tuned AI models for numerous applications, from enhancing customer service with sentiment analysis to improving healthcare with disease recognition using medical imaging data.
The re-use of pre-trained AI models and data for fine-tuning raises ethical and privacy-related concerns. Careful handling and curation of data, model transparency, and informed consent in data usage remain pivotal.





